4주차 - 관측 가능성
개요

결국 새로운 도메인을 사서 해묵은 인증서 문제를 해결했다..
역시 근본 com은 이메일 하나 날라와서 링크 한번 클릭하니까 일사천리더라.
벨기에 도메인... 사진으로 인증하라느니 여권을 찍으라느니..
메일 답장은 오지도 않고..
DOMAIN_NAME=zerotay.com
$CERT_ARN=$(aws acm list-certificates | jq -r '.CertificateSummaryList[] | select(.DomainName == $DOMAIN_NAME).CertificateArn' --arg DOMAIN_NAME $DOMAIN_NAME)
HOST_ZONE=$(aws route53 list-hosted-zones-by-name --dns-name "$DOMAIN_NAME." --query "HostedZones[0].Id" --output text)
api 서버에서 노출하는 메트릭은 무엇이 있나?
이걸 파서 어떤 것들을 볼 수 있나 보자.
콘솔을 통한 모니터링

eks 콘솔에서 쉽게 현재 클러스터에 배포된 리소스들을 확인할 수 있다.

한 리소스에 들어가면 또 이렇게 각종 정보들이 나오기 때문에 나름 편하게 모니터링을 하는데 도움을 준다.
kubectl에 익숙해진 나라는 젊꼰은 그냥 kubectl 쓰련다.

참고로 콘솔에서 클러스터 정보를 확인할 수 있는 이유는 세션에 대해 insight 정책이 붙었기 때문이다.
컨트롤 플레인 로깅
컨트롤 플레인은 사용자가 관리하는 영역이 아니기 때문에 구체적으로 어떻게 모니터링해야 할지 감을 잡기 어렵다.
그렇지만 또 안할 수도 없는 노릇인 게, 임의의 사용자가 접속한다던가, 누군가 클러스터 조작을 못하고 있다면 왜 못하고 있는지 이유를 알아낼 필요가 있다.
테라폼 세팅
create_cloudwatch_log_group = true
cluster_enabled_log_types = [ "audit", "api", "authenticator", "scheduler", "controllerManager"]
테라폼에서는 굉장히 간단하게 세팅이 가능하다.
5개로 분류되는 로그들을 남길 수 있다.
로깅을 하고 싶지 않다면 명시적으로 false라고 설정해줘야 한다.
확인

그러면 클라우드워치에 이렇게 기록이 남게 된다.
이렇게 클라우드워치로 보는 것도, 저장하는 것도 다 비용이라, 필요한 정보만 적절히 로깅하는 것이 중요하다.

많이 경험해보진 않아서 잘은 모르겠으나, 이 정도의 비용이 발생한다는 것 같다.
각 분류 그룹이 어떤 그룹을 담는지 확인해보자.

authenticator에는 eks 클러스터에서 이뤄지는 iam 자격증명과 관련된 로그가 담긴다.

apiserver에는 그냥 api 서버 컨테이너에 남는 로그가 보인다.
api 서버 차원에서 확인해야 하는, crd 등록 여부나 관련 정보는 여기에서 확인하면 된다.

audit에는 api 서버가 남기는 audit 정보가 보인다.
클러스터 내부에서 일어나는 인증 인가와 조작에 대한 정보는 여기에서 확인하면 된다.
보안의 관점에서 로깅이 필요하다면 이 로그는 매우 유의미하다.
어떤 account가 어떤 동작을 했는지 모든 기록이 남기 때문이다.
조금 아쉽게 느껴지는 것은 audit을 어떻게 남길지 커스텀하는 방법이 없는 것.[1]
또한 내 마음대로 규칙을 지정할 수 없으니 여기에는 불필요하다고 느낄 만한 정보도 담겨버릴 것이고, 금새 크기도 불어날 것이다.
E-api 서버 감사에서 확인했을 때 이 데이터는 진짜 무진장 쌓이는데 aws의 장사 심보 아니냐..?
라고 생각하며 찾아봤는데 여기에서도 비슷한 요청과 생각이 보인다..ㅋㅋ[2]

cloud controller manager의 로그도 확인할 수 있다.
서비스를 만들어도 이걸 활용할 일은 없을 것이고, 실질적으로 노드에 대한 정보 확인할 때나 쓸 텐데 그걸 또 로그로 확인할 필요도 없다고 생각한다.
나중에 Karpenter를 사용하면 이게 유용할 일이 있을까?
이거 남기는 건 돈 낭비라고 생각한다.

scheduler의 정보도 남는데, 이건 어차피 이벤트로 정보가 거의 다 남기 때문에 이것도 돈 낭비일 것 같다.

마지막으로 controller manager 로그.
이것도 볼 일이 얼마나 있을까.. 싶긴 하다.
쿠버네티스에서는 코어 컴포넌트에서 에러를 일으킬 만한 동작들이 있다면 웬만해서는 미리 검증 에러를 내거나 이벤트로 표시를 해주기 때문에 이런 로그는 특정 상황이 아니라면 필요하진 않을 것 같다.
log insight 활용

로그 인사이트 기능을 이용해 로그를 쿼리하는 것도 가능하다.
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc

간단하게 audit으로 어떤 유저가 많이 요청을 하는지 확인할 수 있다.

ELB 헬스체커가 많이 동작하는 게 보여서 확인해봤는데 헬스체크에 꽤나 많은 통신이 발생하고 있다.
alb 컨트롤러에서 일으키는 요청이 아닐까 생각했는데, 컨트롤러가 설치되기 이전부터 발생한 요청이기에 컨트롤 플레인의 로드밸런서가 보내는 헬스체크 요청으로 보인다.

이 요청은 public-info-viewer라는 클러스터롤을 통해 허용되며, 인증되지 않은 유저가 접근할 수 있게 돼있다.

요컨대 아무런 인증 수단을 마련하지 않는 요청도 허용되고 있다는 말이다.
당연히 헬스체크야 긴밀하게 이뤄져야 한다고는 생각했지만, 1시간에 12000개가 생길 것이라곤 생각하지 못했다.
1분에 2000번의 헬스체크?
1초에 한번씩 각 노드가 api서버에 /livez /readyz를 날린다고 해보자.
나는 지금 노드가 3개 있고, 컨트롤 플레인 내부에서도 해당 요청을 날릴 수도 있으니 노드는 총 6개라 생각해보면 1분에 날아가는 요청 개수는 360개이다.
여기에 api 서버 앞단의 로드 밸런서가 날릴 요청까지도 생각해도 이게.. 1분에 2000번이 발생할 수가 있나?
또 어떤 컴포넌트가 api 서버 헬스체크를 수행할까?
잘 모르겠지만, 일단 이에 대한 로그를 남기면 비용이 커질 것 같다.
추가적으로 이 트래픽 비용도 사용자가 부담하는 거라면 상당히 부담될 것 같은데..
조금 더 알아봐야겠지만 불필요한 헬스체크가 일어나고 있는 것은 아닐까 우려된다.
audit 정책을 커스텀할 수 없게 한 것은 악랄하다고 생각한다.
이건 쿠버네티스 차원에서 동적 설정까지 지원해주는 건데 사용자에게 이를 전달할 수 있는 인터페이스만 마련해주면 되는 거 아닌가.
웹훅도 지원 안 해주고(물론 웹훅은 설정하는 게 더 비용이 나갈 수도 있다), audit을 받아보려면 무조건 쌓이는 헬스체크까지 받아야 한다니..
k get --raw /metrics
참고로 프로메테우스 형식으로 몇 가지 지표를 받아볼 수 있다.
여기에는 etcd 사이즈, scheduler, controller의 정보가 담긴다.
이건 나중에 보도록 하자.
CloudWatch Container Observability
이건 애드온이다.
이걸 세팅하면 cloudwatch agent 파드와 fluentbit 파드가 데몬셋으로 배포되면 각 노드의 메트릭과 로그를 수집하게 된다.
(fluent bit은 fluentd와 호환되면서 훨씬 가벼운 로그 수집기라고 한다.)

https://aws.amazon.com/ko/blogs/mt/new-container-insights-with-enhanced-observability-for-amazon-eks/

구조는 대충 이렇게 돼있다.
https://aws.amazon.com/ko/blogs/containers/fluent-bit-integration-in-cloudwatch-container-insights-for-eks/
구체적으로는 세ㅏ지를 수집한다.
application
노드
데이터플레인
테라폼 세팅
####################################################
##### Amazone CloudWatch Observability
####################################################
resource "aws_eks_addon" "cloudwatch_observability" {
cluster_name = module.eks.cluster_name
addon_name = "amazon-cloudwatch-observability"
addon_version = "v3.3.0-eksbuild.1"
resolve_conflicts_on_update = "PRESERVE"
configuration_values = jsonencode({
agent = {
mode = "daemonset"
}
})
service_account_role_arn = module.cco_irsa.iam_role_arn
}
module "cco_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "5.52.2"
role_name = "cco"
attach_cloudwatch_observability_policy = true
force_detach_policies = true
oidc_providers = {
eks = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["amazon-cloudwatch:cloudwatch-agent"]
}
}
}
여타 다른 애드온 설정해주듯이 설정을 해줬다.
configuration에서, 기본이 데몬셋이라 저렇게 설정할 필요는 없지만 statefuleset과 deployment도 사용할 수 있길래 그냥 신기해서 넣어봤다.
확인

세팅이 완료되면 amazon-cloudwatch라는 네임스페이스의 많은 리소스들이 배포된다.
k stern -n amazon-cloudwatch cloud

정책 구성도 완료됐다면 이런 식으로 뜬다.
만약 빨간색이 있다면 정책 설정 여부를 확인하자.

클라우드워치로 가보면 로그 그룹에 이렇게 세 항목이 추가된 것이 보인다.

제대로 설정이 완료되면 이렇게 cloudwatch container insight에서 모니터링이 가능해진다.
이전 실습 때 만들었던 클러스터가 아직도 표시가 되고 있는데, 이건 왜 이런지 잘 모르겠다.

이 친구는 꽤나 괜찮은 것 같은데, 클러스터에 대한 각종 정보를 간편하게 보는 것이 가능하다.

아래에 클러스터를 하나 특정해서 보면 내용물을 조금 더 구체적으로 확인할 수 잇다.
클러스터 별, 네임스페이스별, 파드별 등 다양한 관점에서 지표를 확인할 수 있어 매우 유용하다고 생각한다.
현재 사진은 클라우드워치 애드온 관련 네임스페이스 정보인데, 자원 사용량이 크지 않은 것이 보인다.

그나마 메모리 사용량이 1.4퍼인 파드 하나를 들어가서 봤는데.. 컨테이너가 68개..?라고 해서 순간 내 눈을 의심했다.
근데 상단에 뜨는 건 클러스터 전체 값인 듯하다.

맵 뷰를 누르면 이렇게 이쁘게 상관 관계를 볼 수 있다.
자원 사용량에 대한 종합적인 표시도 해주고 있어서 편리해보인다.
k -n amazon-cloudwatch get cm fluent-bit-config -o yaml

로그에 대한 정보는 볼 수 없었는데, eks 애드온 관련 컨테이너 로그들을 제외하고 있기 때문이다.

데이터 플레인 로그는 journal 등의 장소에서 담고 있다.
fluent bit은 이렇게 로그를 수집하고, 이것은 cloudwatch agent가 aws로 날려주게 될 것이다.
k -n amazon-cloudwatch get po fluent-bit-w268b -o yaml | yh
이 블로그[3]에서 fluentbit 컨테이너의 보안 취약점에 대해 이야기하는 부분을 확인해서 한번 확인해본다.

해당 글에서 포착한 내용에 따르면 루트 디렉토리에 도커 소켓까지 마운팅을 하고 있다.
이건 확실히 엄청난 위험성을 가지는 설정이기는 하다.
아니 애초에 무슨 깡으로 루트 디렉토리를 마운팅하는 거임?

하지만 1.31버전에서 사용하는 3.3.0 버전에서는 그런 문제를 수정한 것으로 보인다.

다만 내 생각에는 문제가 있던 버전에서도 마운팅 시 readOnly 옵션이 부여되어있지 않았을까 한다.
이러면 최소한 해당 컨테이너에서의 write은 막히기에 당연한 설정이다.
여담으로, rercursiveReadOnly가 disabled된 것도 사실 위험할 수 있다.
E-파드 마운팅 recursiveReadOnly 참조.
kwatch로 간단하게 알림 받기
https://github.com/abahmed/kwatch
kwatch는 클러스터 내의 변화를 감지하고 어플리케이션의 문제가 발생했을 때 알람을 주는 간단한 툴이다.
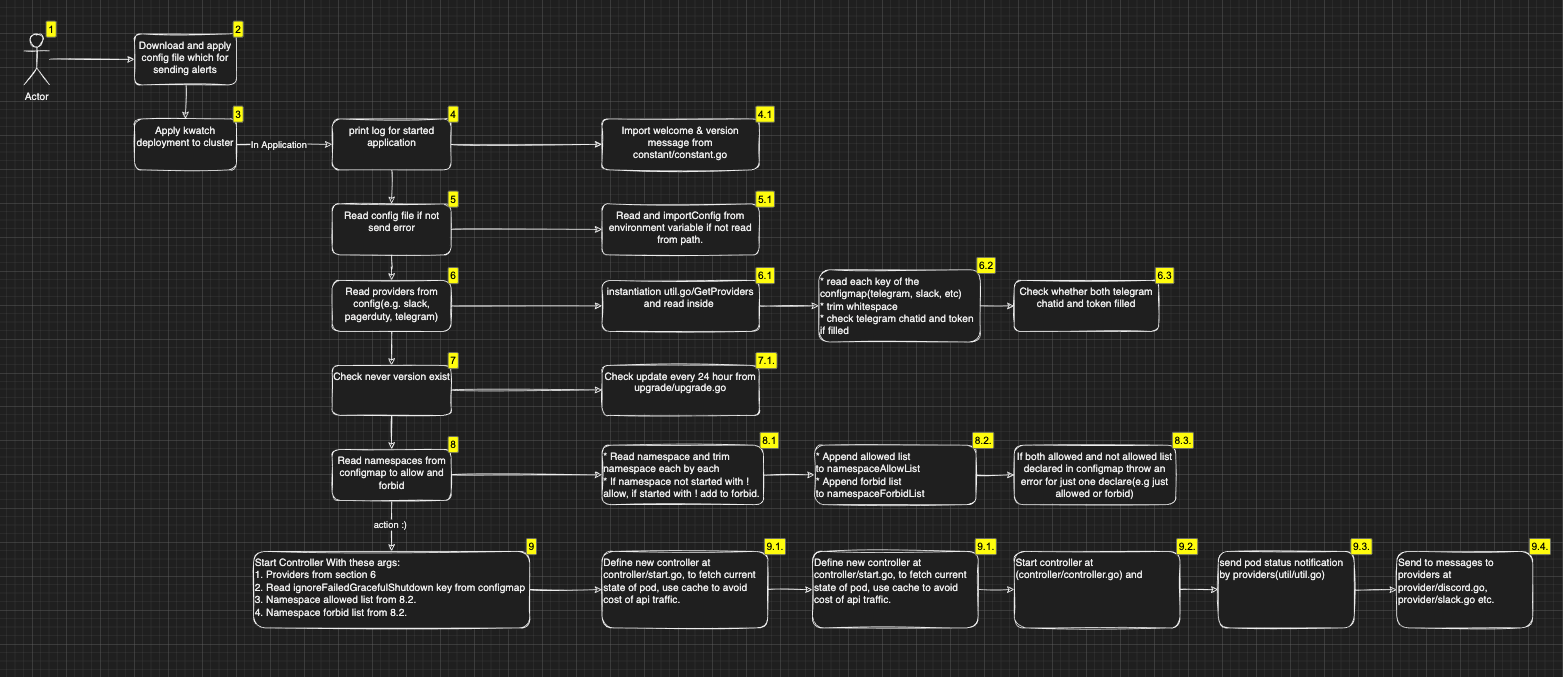
구조가 엄청 복잡하게 생긴 것처럼 보이지만, 실질 로직이 저게 다라서 오히려 사실 엄청 간단한 형식이라 볼 수 있다.
여기에 나와있는 게 그냥 명세서 수준이다..
helm repo add kwatch https://kwatch.dev/charts
helm repo update
helm install kwatch kwatch/kwatch --version 0.10.1

배포는 간단한데, 여기에서 configmap에 대해서 설정해주면 된다.[4]
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
data:
config.yaml: |
alert:
discord:
webhook: https://discord.com/api/webhooks//-q-rp4vGiM7w-b-EO8wMOmuu2UvuXMu_nTE2xCT53T1_bfcas4gkOWf647IV
title: 왈왈
text: 박박

스터디 실습 때는 슬랙에 알림을 보냈는데, 그럼 또 괜히 다른 것도 시도해보고 싶어진단 말이지.
고로 디스코드 방 한 파서 날려본다.

아무렇게나 이미지를 잘못 설정한 파드를 만들었다.
제외할 Reason이나 네임스페이스도 따로 커스텀이 가능하다.
프로메테우스 스택
프로메테우스로 넘어가자!
https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack
여기에 기본 스택 헬름이 있다.
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm show values prometheus-community/kube-prometheus-stack >> prom-stack-helm.yaml
아래 명령어로 values.yaml 파일을 열었는데, 5000줄이다..
어떤 리소스들이 있는지 조금은 알고 싶어서 직접 줄들을 지워가며 살펴봤다.
해당 yaml 파일에 대한 내용은 생략한다.
아래에서 테라폼으로 세팅할 때 내용을 담을 것이다.
# 배포
helm install prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f prom-stack-helm.yaml --create-namespace --namespace monitoring
helm을 통해 그냥 설치할 때는 이런 식으로 해준다.
그라파나의 기본 계정은 admin, prom-operator로 되어있을 것이다.
테라폼 설정
resource "helm_release" "prometheus-stack" {
name = "prometheus-stack"
repository = "https://prometheus-community.github.io/helm-charts"
chart = "kube-prometheus-stack"
version = "69.3.1"
create_namespace = true
namespace = "monitoring"
values = [
<<-EOF
defaultRules:
create: true
grafana:
enabled: true
defaultDashboardsTimezone: Asia/Seoul
adminUser: admin
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/certificate-arn : "${data.aws_acm_certificate.domain.arn}"
alb.ingress.kubernetes.io/group.name : aews
# alb.ingress.kubernetes.io/listen-ports : "[{\"HTTPS\":443}, {\"HTTP\":80}]"
alb.ingress.kubernetes.io/listen-ports : '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name : "${local.cluster_name}-ingress-alb"
alb.ingress.kubernetes.io/scheme : "internet-facing"
alb.ingress.kubernetes.io/ssl-redirect : "443"
alb.ingress.kubernetes.io/success-codes : "200-399"
alb.ingress.kubernetes.io/target-type : "ip"
hosts:
- "grafana.${local.domain_name}"
path: /
persistence:
enabled: true
type: sts
storageClassName: "ebs-csi-default-sc"
accessModes:
- ReadWriteOnce
size: 20Gi
kubernetesServiceMonitors:
enabled: true
coreDns:
enabled: true
service:
enabled: true
port: 9153
targetPort: 9153
ipDualStack:
enabled: false
ipFamilies: ["IPv6", "IPv4"]
ipFamilyPolicy: "PreferDualStack"
kube-state-metrics:
namespaceOverride: ""
rbac:
create: true
releaseLabel: true
prometheus:
monitor:
enabled: true
selfMonitor:
enabled: false
kubeStateMetrics:
enabled: true
prometheus:
enabled: true
agentMode: false
ingress:
enabled: true
annotations:
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/certificate-arn : "${data.aws_acm_certificate.domain.arn}"
alb.ingress.kubernetes.io/group.name : aews
alb.ingress.kubernetes.io/listen-ports : '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name : "${local.cluster_name}-ingress-alb"
alb.ingress.kubernetes.io/scheme : "internet-facing"
alb.ingress.kubernetes.io/ssl-redirect : "443"
alb.ingress.kubernetes.io/success-codes : "200-399"
alb.ingress.kubernetes.io/target-type : "ip"
hosts:
- "prometheus.${local.domain_name}"
paths:
- /*
route:
main:
enabled: false
ingressPerReplica:
enabled: false
prometheusSpec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Delete
whenScaled: Retain
scrapeInterval: "15s"
evaluationInterval: "15s"
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "5GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ebs-csi-default-sc
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
nodeExporter:
enabled: true
operatingSystems:
linux:
enabled: true
forceDeployDashboards: false
kubeApiServer:
enabled: false
kubelet:
enabled: false
kubeControllerManager:
enabled: false
kubeDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: true
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
alertmanager:
enabled: false
windowsMonitoring:
enabled: false
EOF
]
depends_on = [
helm_release.lbc,
helm_release.external_dns
]
}
테라폼에서는 이렇게 세팅해주었다.
yaml 파일이 실습에서 제공해준 것보다 조금 더 길어졌는데, 여러 세팅값을 보면서 그래도 내가 인지하면 좋겠다 싶은 것들을 남겨두었다.
실질적으로 수정을 하진 않았고 그냥 기본값이라 없어도 상관없는 값들도 많다.
기본 확인

왜인지 잘은 모르겠는데, 그라파나는 path에 /만 넣어도 되는 반면 프로메테우스는 /*을 무조건 넣어야만 했다.
그래야 이렇게 설정이 된다.
kubectl get crd | grep monitoring
기본 확인은 대충 건너뛰고, 새로 생긴 crd들만 보자.

이 crd들을 통해 각종 관측 가능성 세팅을 추가적으로 할 수 있게 된다.
모니터라는 crd들은 파드와 서비스에 대해 추가적인 메트릭을 제공할 수 있도록 돕는다.

프로메테우스 도메인으로 들어가, status에 runtime information을 보면 스토리지 관련 설정이 제대로 잡힌 것이 보인다.

config 부분을 보면 rule과 scrape 설정이 어떻게 됐는지 볼 수 있다.
rule의 경우 컨피그맵으로 저장돼있다.
워크로드 메트릭 수집
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: aws-node
특정 파드의 메트릭을 수집하고 싶다면 이렇게 파드모니터를 만든다.
이 설정을 통해 프로메테우스의 설정 파일을 수정하지 않아도 알아서 프로메테우스가 해당 메트릭을 찾을 수 있게 된다.

참고로 당연히 대상으로 잡은 vpc cni 파드는 먼저 메트릭을 노출하고 있는 상태이다.

조금 가디라니 프메 콘솔에서 서비스디스커버리에 방금 만든 녀석이 추가됐다.

타겟으로 잡혀서 헬스 상태도 표시가 되고 있다.

config 파일에서 job으로 이 메트릭을 찾아 보면 sd_config로서 잡히는 것이 확인된다.
경로는 /metric로 잡혀있으니, 여기에서 기본으로 kubeconfig파일을 이용해, kube-system의 파드들을 찾아낸 뒤에 metric이란 경로에 메트릭을 노출하고 있는 파드들의 정보를 긁어모으는 것이다.
프로메테우스가 동적으로 대상을 찾아나서기에 서비스 디스커버리라고 부른다.

이제 관련 메트릭들을 쿼리할 수 있게 됐다!
데몬셋에 대해서는 대체로 이런 식으로 파드 모니터를 써주지만, 다른 워크로드의 경우는 서비스 모니터를 활용하는 것이 더 좋을 수 있다.
왜냐하면 서비스모니터는 해당 서비스의 엔드포인트로 잡힌 대상들을 기준으로 하기 때문에 꺼지고 있거나, 실제 트래픽이 연결되지 않고 있는 파드의 정보를 무시할 수 있기 때문이다.
쿼리
노드 기본
node_cpu_seconds_total{mode="idle"}
노드의 cpu가 사용된 시간을 확인해본다.

노드 별로 두개의 cpu가 있어서 두 개씩 출력되는 게 확인된다.
sum without (cpu) (node_cpu_seconds_total{mode="idle"})

노드 별로만 확인하려면, cpu 라벨을 무시하고 sum을 하면 된다.
node_memory_Active_bytes /1024 /1024

바이트로 보면 불편하니 메가 바이트로 변환하여 현재 메모리 사용량을 보니 300메가 정도를 사용하고 있는 게 보인다.
Kube State Metrics
기본 설치를 할 때 Kube-State-Metrics 역시 설치가 됐기 때문에 이를 활용할 수 있다.ㅣ
kube_deployment_status_replicas{deployment="coredns"}

이런 식으로, kube_라는 접두사를 붙여 메트릭이 잡히고 각 오브젝트들에 대한 상태를 볼 수 있다.
라벨로 다양한 정보를 담고 있어 자유롭게 필터링이 가능할 것이다.
코어 컴포넌트 - coredns 메트릭 확인 후 external dns 수정
대부분의 쿠버네티스의 코어 컴포넌트들은 자체적으로 /metrics로 메트릭을 노출하고 있기 때문에 이것을 통해 쿼리를 날려볼 수도 있다.
k get servicemonitors.monitoring.coreos.com --all-namespaces

프로메테우스 스택을 배포할 때, 관련한 설정이 있는 것을 확인할 수 있는데 이것을 통해 메트릭이 자동으로 수집되기에 서비스의 이름에는 이렇게 긴 이름이 붙게된다.

어차피 자동완성이 지원되기에 굳이 쿼리를 일일히 명시하지는 않겠다.
신기한 게, AAAA레코드로 요청이 들어오는 것도 보인다.

하도 궁금해서 coredns configmap에 log 기능을 활성화해서 확인해봤다.
coredns는 configmap의 변경을 인식하고 동적으로 이를 반영하기에 바로 로그가 남는 것이 보인다.
AAAA와 A레코드로 질의를 날리는 무언가가 있다는 것을 확인했다.

트래픽 낭비의 주범은 바로 external-dns였읍니다..!
앞으로도 많이 쓸 녀석인데 나중에 이 친구 손 좀 봐줘야겠다.
보다 보니 추가적으로 설정해주면 좋을 게, aws로 가야하는 도메인에 대해서도 일단 cluster.local을 붙여대고 앉아있다.
나중에 mutating webhook policy 써서 쿼리 최적화 해본 다음에 이것까지 설정해서 비교해봐야겠다.

간단하게는 external dns의 dns policy를 clusterfirst가 아니도록 바꿔봤다.

샘플로 externaldns를 사용하는 서비스를 몇번 만들 때 요청량이 증가하는 모습이 보였다.
아마도 alb controller의 요청이 집계된 것 같다.
external dns의 쿼리가 coredns로 가지 않게 하는 것만으로도 어마무시하게 요청량이 줄어든 것이 확인된다.

보다시피 로그로도 이제 coredns로 요청이 가지는 않는 것이 보인다.
관측 가능성을 어떻게 확보하냐에 따라 클러스터를 효율적으로 운영할 수 있는 다양한 방법과 전략을 생각할 수 있게 된다.
그라파나
프로메테우스를 열심히 만진 것은, 그라파나로 예쁘게 시각화하기 위한 도움닫기!

그라파나를 보면 왼쪽에 다양한 탭이 있따.
- dashboard - 시각화 템플릿
- explore - promql 등을 활용해 실시간으로 지표 쿼리 날리기
- alerting - 그라파나 alert 기능
- connections - 데이터 소스 설정

스택으로 설치를 했을 때, 기본 데이터 소스로 프로메테우스가 들어가 있는 것을 확인할 수 있다.

또 미리 구성된 대시보드도 많이 제공해주고 있다.

위에서 설정을 바꿔줘서 coredns의 요청이 줄어든 것을 간단하게 확인할 수 있다.
sum(rate(coredns_dns_request_count_total{job=~".*",cluster=~".*",instance=~".*"}[5m])) by (proto) or
sum(rate(coredns_dns_requests_total{job=~".*",cluster=~".*",instance=~".*"}[5m])) by (proto)
해당 그래프는 이렇게 PromQL을 통해 쿼리되어 나오는 데이터이며, 이것이 바로 PromQL을 잘 알아야 하는 이유라고 할 수 있다.
대시보드 가져오기
그라파나에는 여러 사람들이 미리 만들어둔 대시보드를 가져올 수 있다.

대시보드에서 New를 누르고, Import를 누른다.
대시보드는 json 형태로 변환이 가능하기 때문에 json 파일을 올릴 수도 있지만, 그라파나 대시보드 페이지에 이미 공유된 대시보드라면 있는 번호를 이용해서 가져오는 것도 가능하다.

15757 대시보드를 가져와본다.

노드는 3개, 네임스페이스는 5개, 파드는 30개 돌아가고 있다.

상단에 각종 기입칸이 보이는데, 이것들은 대시보드에서 사용할 수 있는 variable이다.
시각화 블록을 만들 때 이걸 활용해 다양하게 시각화하는 것이 또 가능하다.

오잉! 시각화가 제대로 되지 않는 블록이 보인다.

왜 이런 문제가 발생하는지 보려면 결국 쿼리를 만져야 한다.
container_cpu_usage_seconds_total이란 메트릭이 필요한 상황이다.

그러나 프로메테우스에서는 해당 메트릭을 제공하지 않는다.
이건 사전지식이 필요하겠지만, 컨테이너 메트릭 정보는 kubelet이 노출하고 있다.
helm -n monitoring upgrade prometheus-stack prometheus-community/kube-prometheus-stack --reuse-values --set kubelet.enabled=true
기존 설정에서는 kubelet의 데이터를 가져오도록 설정하지 않았으므로, 이를 업데이트 해보자.

이제는 정상적으로 모니터링이 되는 것을 확인할 수 있다.
커스텀 대시보드 - 네임스페이스 대시보드 만들기

스터디 시간에 대시보드를 보면서 네임스페이스 별로 지표를 가져와주는 대시보드가 없으면 내가 만들어야겠다 생각하고 있었는데..
막상 확인해보니 있다..
그런데 내가 생각하는 느낌과 조금 다른 측면도 있다.
그래서 나름의 커스텀 대시보드를 만들어보고자 한다.
무얼 보고 싶은가?
내 목적을 먼저 명확히 한다.
나는 관측가능성을 위한 세팅을 하게 되어 발생하는 리소스를 알고 싶다.
그리고 그것이 전체 클러스터 내에서 얼마나 비중 있는지도 확인하고 싶다.
이를 통해 어떤 툴이 리소스 효율적인지 측정하고 싶다.
대충 이 정도 구상을 해봤다.
그라파나.
네임스페이스 대시보드는 어떻게 만들까?
https://grafana.com/grafana/dashboards/15758-kubernetes-views-namespaces/
중간 결과

....ㅋㅋ
4시간 정도 삽질한 결과다.
저장 안 하고 하다가 다 날려먹고 10분 멍때리다 10분 끄적이다 말았다.
.... 어느 정도 활용법은 알게 됐으니 나중에 보충하자..
하면서 몇가지 어려웠던 것만 짚어보겠다.
- 위와 같이 같은 값을 내야 하는 지표가 미묘하게 다를 때가 있다.
- 어떤 룰은 먼저 노드 별로 값을 나눈 후에 합산하고, 어떤 룰은 전부 합산한 후에 join하는 듯한 연산을 하고.
- 크게 차이가 나진 않지만 근소하게 오차가 있을 때가 있긴 한 것 같다.
- 메트릭들은 프로메테우스 콘솔에서 얼추 검색이 되지만, 룰은 잘 검색이 안 된다.
- 룰을 적극 활용하고 싶었는데, 룰은 또 산더미인데 막상 쿼리로는 자동완성이 잘 안 되는 것 같았다.
- 이건 내가 잘 몰라서 그런 것일 가능성도 크다.
- KSM에서 모든 리소스를 한꺼번에 가져오는 메트릭은 제공하지 않는다.

- 이거 보고 나도 네임스페이스 속 리소스들을 열거하고 싶었는데..
- 이거 만드신 분은 엄청난 노가다를 하신 거였다.
- 각 리소스를 전부 쿼리문으로 만드셨더라..
- 주니어 이슈
- 솔직히 아직까지 어떤 데이터가 중요한 건지 확실하게 감이 잡히지는 않는다.
- 쿠버 리소스는 얼추 알지만, OS 관련 메트릭들이 상당히 많은데 뭐가 뭔지 확 감이 오진 않았다.

- 가령 메모리 관련 메트릭들이 이렇게나 많다.
- 노드 메모리만 해도 더티, 스왑, 액티브, 바운스, 캐시 등등..
- 이걸 다 알고 있다면 왜 내가 취준생이겠냐 싶다가도, 시간 들여서 공부하고 싶다는 생각이 불끈 솟는다.
- 어떤 지표를 어떻게 가시화하는 것이 효과적인가에 대한 고민
- 처음 생각에는 내가 지정한 cpu 임계치를 넘는 파드들만 표시를 하고 싶었다.
- 그런데 생각해보니 임게치에 근접한 파드들도 표시가 되는 식으로, 주변 정보도 담아야 하는 것이 아닌가 하는 생각이 또 들었다.
- 위의 어려운 점과 합쳐 이런 고민들이 쌓이다보니, 생각보다 작업이 빠르게 진행되지 않았다.
- 이런 것도 운영을 하면서, 경험을 쌓으면서 익혀나가는 영역일까 하는 생각이 들었다.
- 마지막으로...
- 하다가 refresh 안 된다고 무작정 새로고침 누르면 안 된다
알람 만들기

마지막으로 그라파나로 해볼 것은 알람이다.

먼저 어디에 보낼지 포인트를 지정한다.

나는 이번에도 딸깍 디스코드로 지정해봤다.

테스트는 성공적이다.
다음으로는 룰을 만들어본다.

kube_pod_container_status_waiting_reason 메트릭은 파드가 크룹백이나 이풀백일 때 생긴다.
그래서 해당 쿼리를 규칙으로 잡아본다.

이 메트릭은 해당 이슈가 발생하지 않으면 아예 생성되지 않기에, 일단 데이터가 없을 때 정상이라고 설정했다.
apiVersion: v1
kind: Pod
metadata:
name: centos
spec:
containers:
- name: centos
image: centos
command: ["sh", "-c", "exit 1"]
지속적으로 컨테이너가 종료돼 CrashLoopBackOff가 일어날 파드를 만든다.

크윽..허접한 파드 때문에 경고가 날아온다!
설정 파일 만져보기 - 서비스디스커버리 설정
컨트롤 플레인 지표 가져오기 -
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/view-raw-metrics.html
https://www.anyflow.net/sw-engineer/prometheus-large-scale-comparison
대박.. 프로메테우스와 다른 솔루션 비교
otel
- 분산 추적 3가지 개념
- 추적 trace 은 요청 또는 트랜잭션과 관련된 활동을 나타내며, 추적 ID trace ID로 고유하게 식별된다.
- 추적은 하나 이상의 서비스에 걸쳐 있는 여러 개의 스팬으로 구성된다.
- 요청 처리의 각 단계를 스팬 span 이라고 하며, 시작 및 종료 타임스팸프로 특징지어지고 추적 ID와 스팬 ID 쌍으로 고유하게 식별된다.
- 태그 tag 는 메타데이터로 요청 URI, 현재 로그인한 사용자의 이름 또는 테넌트 식별자 등 스팬 콘텍스트에 대한 정보를 추가로 제공한다.
- 추적 trace 은 요청 또는 트랜잭션과 관련된 활동을 나타내며, 추적 ID trace ID로 고유하게 식별된다.
ndots 최적화보니까 mutating webhook policy 써보고 싶다
스터디
오늘은 관측가능성 - 이것과 모니터링 차이 정리하자
참고로 콘솔에서 클러스터 볼 수 잇는 권한을 클러스터롤로 볼 수 잇따.
프메 그라 슬 것.
이를 위해 간단 어플리케이션 배포 필요
(이를 위해 무조건 dns 성공해야 한다.)
먼저 로깅
클러스터 관련.
클와에서 로그 그룹확인
로그 인사이트로 쿼리도 가능.
여기는 어떻게 명령을 써서 확인하는지만 살피면 될 것 같다.
etcd 디비 사이즈 보기도 가능
파드 로깅도 할 수 잇따.
nginx로 사용하자
while true; do curl -s http://a5db9220ed11d4c3d9bf1970a208176d-1578417766.ap-northeast-2.elb.amazonaws.com/ | grep title; date; sleep 1; done
nginx 헬름은 에러 로그를 하나로 보으고 있다.
도커 문서에 로그를 저장하는 권장 패턴이 나와있따.
cci
클와로 파드 로그, 노드 로그도 넣을 수 잇따.
fluentbit
클와 애드온으로 메트릭, fluentbit으로 로그 전송.
이걸로 클와에서 확인 가능

어플이 파드, 호스트는 노드 자체, 데이터플레인은 워커 노드로서의 메트릭
이런 식으로 가져온다.
fluent bit 설정은 cm으로 되는데, 동적 설정이 가능한가?
ab 툴로 쉽게 부하를 줄 수 있따.
로그 인사이트로 가보면, 어플 부분에 들어가서 확인할 수 잇따.

클와에는 컨테이너 인사이트라는 것도 있다.
ㅑ
다음은 알람 기능
NICK=Zerotay
# configmap 생성
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/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'
title: $NICK-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.10.1/deploy/deploy.yaml
ㅑ
가장 중요한 건, 프메 스택 부분.
이번에 무조건 프메 완벽 정리한다.
프메, 그라 얼럿 차이 살짞만 짚고 그라 얼럿만 쓰자.
tsdb
내부적으로 샤딩, 청크를 한다고 한다.
익스포터를 하는 건 좋은데, 쿠버 관련 정보를 하는건 쉽지 않다.
그래서 서비스 디스커버리가 있다.
타겟을 자동 등록하는 것.
그래서 프메 오퍼레이터를 쓰는 것이ㅏㄷ.
여기에 쿠버를 디스커버리로 삼으면 관련한 데이터를 가져올 수 있게 된다.
현재는 3.0 버전
로컬에 설치해보기.
잡단위로 구분된다.
프메 슨택으로 컨플도 수집?
그럼 클와로 보는 것보다 개이득아닌가?
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/view-raw-metrics.html

오픈 메트릭 관련 지표도 얻을 수있게 돼있다.
파드에 대해서는 파드 라벨을 이용한 파드모니터 오브젝트
서비스에 대해선? 서비스모니터를 쓴다.
이때 엔드포인트를 이용한다.
그래서 살아있는 파드만 가져온다.
이를 통해 서비스에 대해서 할 때 유용함.
그냥 파드모니터 쓰면 죽은 파드까지 수집될 수 있음

이놈은 자동 리로더가 있따.
프롬ql 관련 설명도 있음
프롬ql은 아는게중요.
그파 id 17900써보자.
근데 이거 cpu 잘 안나온다.

여기에 프롬ql이 들어ㅏ깅ㅆ따.
이런 거 커스텀하려면 결국 알아야함.
node 익스포터관련.
kubestate metric
이건 클러스터 메트릭 내용.
줄여서 ksm이라 한다.
이건 kubeapiserver와 통신해서 값을 가져온다.
데이터 수집 방식.
하나는 익스포터로 엔드포인트 노출
kubeproxy는 어플 자체에 내장됨 - coredns도
헬름은 설정 업뎃할 때 reuse할 수 잇따.

프메는 기본으로 메트릭 유형이 4개
게이지, 카운터, 서머리, 히스토그램
인스턴스 벡터와 레인지벡터
인스턴스는 시점에 대한 메트릭값만 가짐
레인지는 시간의 구간 ([2m] 하던 거)
이제 그라파나 보자.
그라파나에서 동적으로 변수를 받아올 수 잇따.
맨 위에 값을 받는 부분이 변수가 된다.
쿼리에는 $로 세팅되는 부분을 말한다.

그라파나에서느 여기로 커스텀할 수 있다.

기본으로 이렇게 가져오는 게 보인다.
이걸 수정해야 제대로 반영될 것이다.
https://kubernetes.io/docs/concepts/cluster-administration/system-metrics/
프메 형태로 이미 다양한 메트릭 경로를 노출 중.
https://github.com/kubernetes/kubernetes/blob/de7708f06e11efe1140805f1eb4814f358a8d31e/pkg/kubelet/metrics/metrics.go#L1013
실제로 다양한 메트릭을 미리 정의해둔채, Mustregister를 하고 있다.

MustRegister 자체는 인터페이스이고, 이게 실제 구현체인 듯하다.
while true; do curl -s http://a5db9220ed11d4c3d9bf1970a208176d-1578417766.ap-northeast-2.elb.amazonaws.com/ -I | head -n 1; date; done

이런 식으로 얼러트 가능
오픈텔레메트리도 좋다고 한다.
근데 이게 프메 그라파나와 다르게 좋은 점이 있는 건가?
프메 그라를 조금 더 마스터 하는게 좋지 않을까?
보니까 이걸로 로깅이고 뭐고 ㅎ다할 수 잇는 거 같은데.
오텔이 로깅, 분산 추적을 도와주는 툴인가 보다.
파일
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/myeks-4week.yaml
# 변수 지정
CLUSTER_NAME=myeks
SSHKEYNAME=zero
MYACCESSKEY=
MYSECRETKEY=
WorkerNodeInstanceType=t3.large
# CloudFormation 스택 배포
aws cloudformation deploy --template-file myeks-4week.yaml --stack-name $CLUSTER_NAME --parameter-overrides KeyName=$SSHKEYNAME SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=$MYACCESSKEY MyIamUserSecretAccessKey=$MYSECRETKEY ClusterBaseName=$CLUSTER_NAME WorkerNodeInstanceType=$WorkerNodeInstanceType --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 작업용 EC2 IP 출력
aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text
# 운영서버 EC2 SSH 접속
ssh $(aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# cloud-init 실행 과정 로그 확인
tail -f /var/log/cloud-init-output.log
# eks 설정 파일 확인
cat myeks.yaml
# cloud-init 정상 완료 후 eksctl 실행 과정 로그 확인
tail -f /root/create-eks.log
#
exit
# 인스턴스 정보 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].{InstanceID:InstanceId, PublicIPAdd:PublicIpAddress, PrivateIPAdd:PrivateIpAddress, InstanceName:Tags[?Key=='Name']|[0].Value, Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
# EC2 공인 IP 변수 지정
export N1=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2a" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N2=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2b" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N3=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2c" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export MNSGID=$(aws ec2 describe-security-groups --filters "Name=group-name,Values=*remoteAccess*" --query 'SecurityGroups[*].GroupId' --output text)
# 해당 보안그룹 inbound 에 자신의 집 공인 IP 룰 추가
aws ec2 authorize-security-group-ingress --group-id $MNSGID --protocol '-1' --cidr $(curl -s ipinfo.io/ip)/32
# 해당 보안그룹 inbound 에 운영서버 내부 IP 룰 추가
aws ec2 authorize-security-group-ingress --group-id $MNSGID --protocol '-1' --cidr 172.20.1.100/32
# 워커 노드 SSH 접속
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh -o StrictHostKeyChecking=no ec2-user@$i hostname; echo; done
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
labels:
app.kubernetes.io/name: bookinfo
name: bookinfo
spec:
ingressClassName: alb
rules:
- host: bookinfo.$MyDomain
http:
paths:
- backend:
service:
name: productpage
port:
number: 9080
path: /
pathType: Prefix
EOF
kubectl get ingress
# bookinfo 접속 정보 확인
echo -e "bookinfo URL = https://bookinfo.$MyDomain/productpage"
open "https://bookinfo.$MyDomain/productpage" # macOS
# Bookinfo 애플리케이션 배포
kubectl apply -f https://raw.githubusercontent.com/istio/istio/refs/heads/master/samples/bookinfo/platform/kube/bookinfo.yaml
# 확인
kubectl get all,sa
# ratings 파드에서 product 웹 접속(Service:ClusterIP) 확인
kubectl exec "$(kubectl get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}')" -c ratings -- curl -sS productpage:9080/productpage | grep -o "<title>.*</title>"
# productpage 서비스 NodePort 30003 설정
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: productpage
labels:
app: productpage
service: productpage
spec:
type: NodePort
ports:
- name: http
nodePort: 30003
port: 9080
selector:
app: productpage
EOF
# productpage 서비스 NodePort 30003 접속
echo "http://127.0.0.1:30003/productpage"
open http://127.0.0.1:30003/productpage
# 로그
kubectl stern -l app=productpage
혹은
kubectl log -l app=productpage -f
# NodePort 를 통한 반복 접속
while true; do curl -s http://127.0.0.1:30003/productpage | grep -o "<title>.*</title>" ; echo "--------------" ; sleep 1; done
for i in {1..100}; do curl -s http://127.0.0.1:30003/productpage | grep -o "<title>.*</title>" ; done
# (참고) bookinfo 삭제
kubectl delete -f https://raw.githubusercontent.com/istio/istio/refs/heads/master/samples/bookinfo/platform/kube/bookinfo.yaml
# 모든 로깅 활성화
aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
# 로그 그룹 확인
aws logs describe-log-groups | jq
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
관련 문서
| 이름 | noteType | created |
|---|